
Throughout the Internet, we consume millions of images per day. Photos, cartoons, animations, icons, logos, infographics and diagrams to name a few. As the saying goes, pictures are worth a thousand words and that explains why the world is a big fan of images as a content. Photos capture moments & memories, logos build brands, cartoons entertain, infographics provide information in a rich way, icons and diagrams make it easier to understand the meaning and the impact of numbers in data. In this two-part series of articles, we look at how exactly a digital device stores and works with images in part 1 and we look at why there are so many different formats of images such as JPEG, PNG, SVG, GIF, TIFF and so on in part 2.
Magnifying into the world of images

In the real world, images are a lively harmony of continuous blocks of paint. The paint may be through an artist’s brush or printed ink. What looks like a continuous block however is not continuous anymore once we put a painting or a printed ink picture under magnifying lens. A painting will come alive as a series of strokes, used by the painter to piece together the scene. By looking at the strokes, we are able to appreciate the effort put in by the painter. Likewise in the printed world, printing machines place a series of dots densely together. Under a magnifying glass, we can see how different types of printers use different densities of dots for a single inch of a printout.
![]()
For a computer too, there is a way to represent an image. A computer or a phone screen is made of super-tiny individual electronic units called pixels, each of which can be turned on in one of several million colours. A display appears smoother and more pleasant if it has more pixels per inch of screen, also called the density. Likewise, the number of colours each pixel can represent depends on a quantity called bit-depth. The more the number of bits used to represent the colour of a pixel, more the number of possible colours that can be shown and the less blocky the image appears.
How a computer stores an image

We just talked about how for a computer display, an image is just a series of pixels arranged together. An image can be represented by a rectangular matrix of colours, each element storing the colour of a pixel. So if an image is 320 pixels wide and 200 pixels high, there are 320 x 200 pixels in the image, each with a different colour. This would make up a tabular representation of colours in the image. E.g. the 118th row and the 79th column is a pixel of blue colour. Such a representation is called a bitmap or a rasterised image.

There is however another way to represent images, which is applicable especially to diagrams and icons. This is the type of representation that we use when we learn drawing as kids. E.g. to draw a cat, we stack up a smaller circle on top of a larger circle for a body and a head and then draw two triangles of top of the head circle to show ears. We draw tiny circles in the head to represent eyes and a long curved line at the bottom to show a tail. There is no focus on shading, shadows or lighting. While not ideal for photographed scenes, the majority of the world’s image requirements can be fit into such a simplistic view, where an image can be represented by its component shapes. This extends way beyond kindergarten cats. E.g. company logos are generally shapes in solid colours or simple gradients and shadows. Charts, graphs and block diagrams also fit the bill.
Using shapes to represent the components of a picture is called vector graphics. One of the biggest project in the world to use vector graphics is Google Maps in the Map mode. In the early days, Google represented everything as square tiles of bitmap images. But once they figured out how all the components such as roads, building icons and forest patches in the Map mode could be represented as shapes, they switched to vector graphics. This proved to be a huge boon for them, especially when users started using Maps on the road from phones with low bandwidth Internet connections. We will see why I am calling it a boon in the next two sections.
In the next sections, we analyse the advantages and disadvantages of bitmap and vector formats.
Advantages and disadvantages of a bitmap format
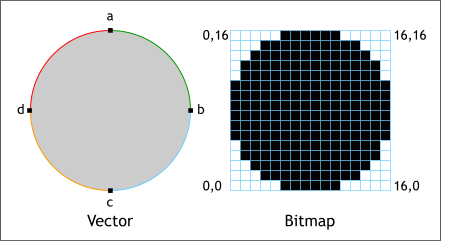
As discussed earlier, a bitmap image stores a rectangular matrix of the the colour of each pixel of an image and measuring image width by image height.
The advantage of this method is that this is the format expected by the digital device’s (computer, phone or tablet) display. The data can be taken as it is and painted directly to the screen with no further processing. However there are a couple of disadvantages. Since bitmaps are the exact pixel-by-pixel descriptions of images, resizing a bitmap can be problematic. E.g. Let’s say that a bitmap measures 800 pixels in width. Now if we try to resize it to 400 pixels, the software has to take a decision on which original pixels to drop from the final output. Likewise, if we decide to resize the image to 1000 pixels, the software again has to make way for 200 extra pixels and take its best guess on which colours to fill those pixels with, so that the output looks as natural and proportional as possible. Due to this guesswork, altering the size of a bitmap from its original size will cause the image to show up blockily, also known as a pixelation, noticeable especially in a curvy image, where jagged edges begin to show.
Also, the more the size of the bitmap, the more disk space and memory it takes, which means that transferring big images over a slow network becomes a problem and trade-offs must be done between size and quality.
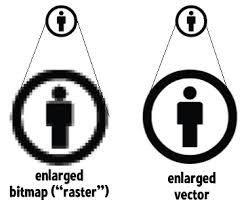
Vector images on the other hand are simply descriptions of images in terms of shapes, e.g. orange coloured rectangle of size 200. This means that it can be easily resized based on demand. E.g. to reduce the image into half its original size, the rectangle’s description can simply be updated to size 100 with a simple math calculation. Secondly, since the image file does not store a detailed pixel by pixel description of the image, the size of the file on disk and subsequently loaded in memory is extremely light. This is especially useful when sending files over Internet.
However, digital displays ultimately require that an image be described as a pixel by pixel rectangle. Hence, the software that supports vector images is responsible for converting the shape descriptions into a pixel bitmap. This process is called rasterisation. So, the software that works with vector graphics must know how to rasterise them.
This does lead to a third advantage for vector graphics though. Because the image is only converted from shapes to pixels during when the image is drawn to the screen, rather than when the image is stored, there is no guesswork due to change in size, and a vector image is rendered smoothly whether it is shrunk or enlarged.
Conclusion
In summary, we have seen how digital devices work with images, how images can be represented and stored in files and how these files are in turn used by the device’s software. In the next post, we shall see the purpose for the different bitmap formats such as JPEG, PNG and GIF and the different vector formats such as SVG.