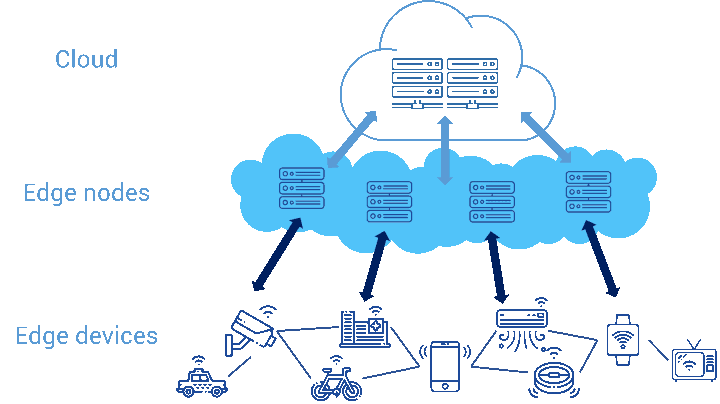
How do we define edge computing? Picture yourself as the chef of a big restaurant in your city. You have hired 16 junior chefs. But they are new to restaurant cooking and are so low on confidence. For each step in each recipe, they run to you for approval. One junior chef comes to you with a spoonful of soup every time he adds some spice to verify if it still tastes right. Another chef rushes to you every time she adds some sugar to cake batter. Not only are you overworked as 16 chefs rush to you all day for validation, but the chefs themselves have run themselves ragged between their counters and your counter.
What if instead you told them, “I have faith in all of you. I hired you because you are all good learners with promise of greatness. I provide you complete autonomy in your day-to-day cooking. I will provide you with the recipes. But while cooking, you be the judge of the taste, texture and temperature. You don’t need my validation for every step. Come to me only if a customer complains about a dish. I will then intervene and take care of the customer. And help you improve.”
You have just established the groundwork for edge computing within your restaurant, where each junior chef uses his / her own expertise to complete a dish. You will just oversee their learning and guide them when they go wrong.
In my 100th Tech 101 blog post, I am writing about a topic that I am yet to cover — Machine Learning. With the field now fairly mature and plenty of programming languages and companies supporting it with excellent software, it is high time for me to educate my readers on what exactly machine learning is.
In layman language, machine learning is a branch of artificial intelligence. Machine learning uses statistical methods, a branch of mathematics. It enables a computer to recognise patterns from data. Using machine learning, a computer make predictions from data, based on previous data that it has already learnt from. Let’s learn more. Continue reading “Machine Learning: A primer”
Let’s imagine that you liked a bicycle at a sports shop and ordered one to be shipped to your home. How would you like it if the shop shipped everything seperately? The frame is in one box, while the wheels are in another. The gears and chain are a tangle, while the handlebar is just a stick with two rubber ends. The seat is a disembodied piece of cushion. Would you be happy with the sports shop and buy from them ever again? No, you’d love it if they ship it completely assembled. You want them to deliver it to you so that you are ready to go. The only fixing you would want to do is some tuning to the brakes and some adjustment to the seat height.
So why should software be any different? Why is it that when we install something, we should have to take care of installing the dependencies, hoping that they don’t clash with those of other applications? One app requires .NET run time version 4, but a new one you are about to install requires .NET run time 5. An app on Linux requires ImageMagick library, so now you have to go find it and install it first. To install Mac OS applications with dependencies, you need to learn about the entire ‘brew’ system.
What if someone simply ships an entire working app with all its dependencies as part of a ‘box’. Just like your bicycle, where the sports shop takes care of assembling the wheels, handlebar, gears, chain and the seat to the frame. That is the concept of containerised apps, these days made popular by Docker. Continue reading “There is a container for that!”
So far, we have talked about short distance communication methods where a fairly powerful radio transmitter is used to communicate with devices within a room or in the next room. Today, we will see a method which is effective only when the devices are within millimetres or at most centimetres of each other? Why would you need communication over such an ultra-short distance at all? Let’s find out. Continue reading “When devices whisper to each other – Part 4: Near Field Communication (NFC)”
In the last post in this series, I elaborated why it is useful to have short distance communication. In this post, we will look at how classic Bluetooth works. Nearly every electronic device today supports Bluetooth. Some people use it more than others. But what exactly is Bluetooth and when is it useful? Let’s see in this post. We will cover only classic Bluetooth and not the latest Bluetooth Low Energy, also called Bluetooth Smart. Continue reading “When devices whisper to each other – Part 2: Classic Bluetooth”
Hello Internet. Today I am starting a series of posts that will explain how devices whisper to each other. Er.. what does that mean? Well, when devices are within a few millimetres to single digits of metres of each other, they don’t need to shout out, do they? That’s why we are learning about a few communication protocols that are used when devices are near each other.
“But isn’t it better that devices are able to communicate from really far away? What’s the point if they just communicate when really close?” Bear with me, as I am going to give you some good reasons for why devices should communicate only when close to each other. Continue reading “When devices whisper to each other – Part 1: Intro”
You have probably seen ways in which the physical world represents digital data in print. The one you are most familiar with is perhaps bar codes. You see them on products at a shopping mall. The checkout counter scans them and fetches the information about the product from a database. Even books have their ISBN codes printed in a bar code.
Over the last decade, another technology named QR or Quick Response code has gained popularity. While traditional bar codes are 1-dimensional and can represent at best between 16 – 20 characters of data, QR falls under a group of data encoding technology called the ‘data-matrix code’ or colloquially, ‘2-dimensional bar codes’. QR codes were pioneered by the Japanese company, Denso wave.
QR codes are capable of holding 7089 characters of data. You can see QR codes all over the Internet, on packaging, on information booklets and even on branding boards at shops. They usually serve as a way to encode URLs so that the user can get further information about a product or an organisation. But URLs are not the only thing possible inside a QR code. Let’s see how they work. Continue reading “How QR codes work”
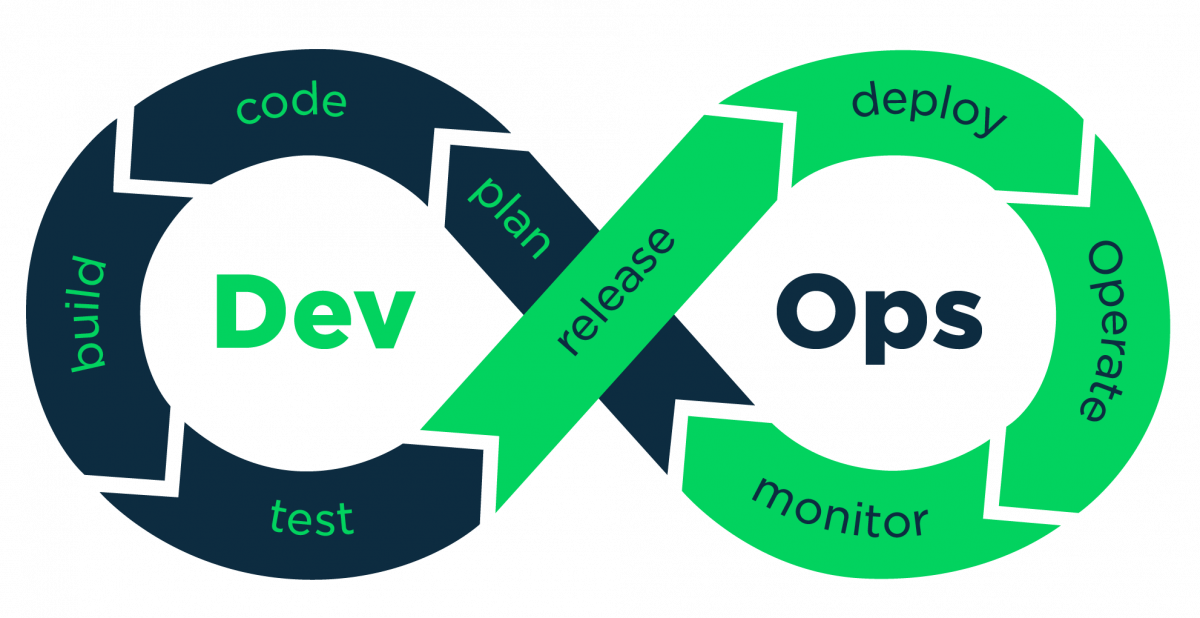
As one of the latest catchwords in the world of software, DevOps is a term that has been growing in popularity over the last decade. Is it yet another meaningless jargon which will fade away when the fashion wears off (Blu Ray discs, are you listening?!). Or is it something really useful, practical, helpful and here to stay for generations to come?
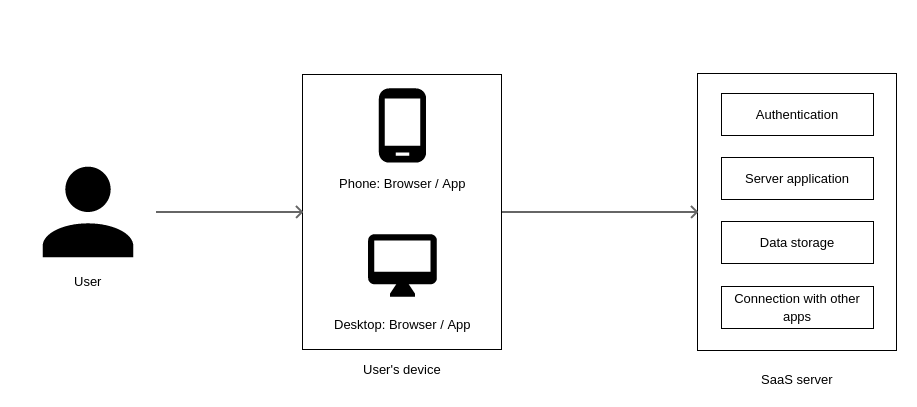
The world of software and information technology throws up jargon at an explosive rate today. It is hard to keep up with them and even harder to understand what they mean. One such term is SaaS or Software as a Service. Let me explain what it means and how it is important to you.
What is SaaS?
SaaS refers to a software that MANDATORILY has the following properties.
The core of the service runs over the Internet on a server, while the user works with a bare-bones tool on his/her device.
Usually nothing is installed on the user’s device and a browser is used to connect to the service. Even if something needs to be installed, it is just a small app with a user interface and a set of functions that connect to the Internet to exchange data with the service’s server. No service functionality resides inside the app.
No storage happens on the user’s device. All of the user’s data is stored on the server securely.
The user needs to connect to the Internet and login to an account in order to use the service and access his/her data.
Due to the service being on the Internet, a user can access his/her data from any device from any location, be it on a smartphone from a car seat, on the home desktop computer or on a laptop from a resort.
As a result, changes made from one device are almost immediately available on another device.
Functionality can be extended on a daily basis because all the functional code is on the server. The user doesn’t have to install a new version on his/her device. In case of a web application via a browser, even the UI can be updated frequently without the user having to install anything.
The layers of SaaS
This is contrast to a traditional desktop software application, where a huge software application with UI and all the functionality is installed on the device’s storage, all the files are stored locally on the device’s storage device and the user needs to remember to copy the files to a portable storage unit such as a thumb drive in order to transfer them from one device to another. Changes also need to be synced among devices every time. Changes to functionality are released as a new version of the application and they too need to be installed on the server.
Additional features
Apart from the above features which are mandatory, Saas MAY provide some of the following features
Limited offline access to use the service when Internet is down.
The ability to download files to local storage.
The ability to connect one SaaS to another in order to use the features / content of one in another. E.g. Pixlr can use your Google Drive as storage.
Ability to share your files with other accounts as read-only or read/write.
Examples of Saas and equivalent desktop applications
The biggest failure of SaaS is when going for long periods of time without Internet. While some SaaSes allow you to edit your content offline, your content will not be synced to the server. So if another person makes changes to the same files from another device, there will be conflicts.
An insecurely set up SaaS can cause a risk where contents can be snooped and even downloaded by unauthorised persons.
All the data is in the hands of the company providing the SaaS and not in your control. A change of policy or an infrastructure collapse can lead to loss of your data.
What you need to build your own SaaS
If you are a company who wants to build your own SaaS, the following should be your technical know-how. There are further requirements such as strong policies and legal agreements which are beyond the scope of this post.
Setting up your own server either in physical form or on a cloud service such as Linode, Rackspace, Amazon Web Services or Google Cloud Compute.
Complete knowledge of HTTP protocol. The app on the device and the server communicate using HTTP.
Securing your HTTP communications using HTTPS.
Programming on the server side using one of NodeJS / Python / Java / Ruby / PHP / .NET.
Using server side file system and databases for data storage.
Using OAuth to validate users who log in and to reject users who are either no signed in or are using invalid credentials.
Using OAuth to allow other apps and users to access a given user’s data.
If you are making a web application for the user’s browser, then your knowledge of HTML, Javascript and CSS should be strong.
If you are making platform-specific apps, then here are your requirements.
Java / Kotlin programming for Android
Swift programming for iOS
.NET programming for Windows
Cocoa application programming for MacOS.
QT / GNOME using C++ or Python for Linux.
Usage of Continuous Integration and Continuous Delivery to roll out new versions.
System administration for the following requirements.
Monitoring the server to make sure that things run smoothly.
Frequent backing up so that data can be recovered.
Conclusion
Being the trendsetter of the last decade, SaaS is now commonplace since 2010 or so, when rich web applications, Android and iOS took the world by storm. There was a need to access apps and their data from anywhere to which SaaS provides the solution. And that need and the success of SaaS is not going away anytime soon.