How do we define edge computing? Picture yourself as the chef of a big restaurant in your city. You have hired 16 junior chefs. But they are new to restaurant cooking and are so low on confidence. For each step in each recipe, they run to you for approval. One junior chef comes to you with a spoonful of soup every time he adds some spice to verify if it still tastes right. Another chef rushes to you every time she adds some sugar to cake batter. Not only are you overworked as 16 chefs rush to you all day for validation, but the chefs themselves have run themselves ragged between their counters and your counter.
What if instead you told them, “I have faith in all of you. I hired you because you are all good learners with promise of greatness. I provide you complete autonomy in your day-to-day cooking. I will provide you with the recipes. But while cooking, you be the judge of the taste, texture and temperature. You don’t need my validation for every step. Come to me only if a customer complains about a dish. I will then intervene and take care of the customer. And help you improve.”
You have just established the groundwork for edge computing within your restaurant, where each junior chef uses his / her own expertise to complete a dish. You will just oversee their learning and guide them when they go wrong.
Formally, what is edge computing?
Here is the formal definition of edge computing.
Edge computing is a distributed computing paradigm which brings computation and data storage closer to the location where it is needed, to improve response times and save bandwidth.
Quite clear, isn’t it? No? Didn’t understand? Well, nor did I. Not a word of it. So true to the mission of Tech 101, I dedicate the rest of the post in explaining edge computing to you in as simple a language as possible.
In plain English, what is edge computing?
Let’s turn back to your restaurant. Notice how you empowered your junior chefs to their own decisions. Here are the drawbacks of highly dependent junior chefs and the benefits of empowered junior chefs.

In the empowered model, the decisions are being made as close to the food as possible. The junior chef no longer leaves his/her counter for validation from you, who are away from where the food is being cooked. As a result, there is no delay between some change in the food and it’s validation.
In the dependent arrangement, if a junior chef adds some salt, he feels obliged to take a small sample to you for validation. The time between the addition of salt and your approval is several seconds. The delay is additional for chefs who have to queue up in front of you because another chef is seeking a validation already. You become a bottleneck for the progress of food preparation.
With the empowered arrangement, you provide them with benchmarks on good taste, i.e. recipes and guidelines. So each junior chef makes a change to the food item being prepared, then samples it and validates it him/herself. No more latency.
There are certain food items like barfi, where a small moment is the right time to stop cooking. If you cook beyond that moment, then the dish is ruined. In the dependent arrangement, what if a junior cook takes a sample from her cooking pan for your approval? While she is away seeking your approval, the residual heat in the pan is cooking the dish further and ruining it. In the autonomous arrangement, she knows right time to take the dish off the pan immediately. And takes the dish off the heat without your approval. At just the right time. No delay seeking your approval.
In the dependent model, what would happen if you were to step away? The junior chefs will be paralysed and will stop cooking. They’ll wait until you return. The functioning of the entire kitchen depends on your availability. But in the new model, the kitchen will continue to function courtesy of your junior chefs, while you can step away for some work of your own, such as a meeting with an important sponsor agent or an order for a wedding party.
This is what edge computing tries to achieve. It puts more processing power, storage, memory and algorithms inside or very close to devices where the action is happening and where the data gets generated, so that a central server somewhere far away in a cloud doesn’t have to bear the brunt of all the decision making.
Internet of Things: the basis for edge computing
In the days of traditional web browsing with desktop computers, laptops and mobile phones, it made to sense to keep things light on your browser or app, making the server application more powerful. The number of devices connecting to the server was in millions, a miniscule number compared to what it is today.
Today, with the progress of the Internet of Things, more devices connect to the Internet, to servers and to online services. I can vouch for this from my own home. 15 years ago, when I first configured Wi-Fi at my home, the only devices connecting to my Wi-Fi router were my home desktop computer and my personal laptop. And I was single. Today, I am married and technology has changed. My home Wi-Fi router takes both my and my wife’s laptops and smartphones. 4 already. In addition, guests drop in with their phones. Then there is our Echo Dot. And there will be many more as we get more devices in the future, such as smart home controllers, wireless speakers, smart TV, Internet-enabled set top box, etc.
Domestic use is too simple a case. But if such simple home usage has expanded in scope so widely, what about industrial usage? Almost everything they install is connected to the Internet and has a touch panel. Each of them send volumes of data throughout the day from their multiple sensors to their respective cloud servers.
Problems with central decision making
Here is some info about your Amazon Echo Dot or Google Home. Neither device has plenty of storage, processing power or memory. Whatever you speak and listen is actually processed by the cloud computers in Amazon and Google respectively. Try using an Echo Dot or Google Home with Internet cut off. The devices will stop working.
Every instruction you issue to these devices is sent as sound data to their respective cloud servers. The cloud servers break down the sound, interpret the command, find a matching response and send the response to the devices along with the data required. With the central servers cut off, these devices are just beautiful bricks. The entire processing and logic is on the servers. In fact, that’s the case with the majority of the IoT devices.
As with every junior chef seeking your approval, every request in a centralised system needs to go through the central server for a solution. Hordes of devices bombard requests, which queue up. There will be a delay for many of the responses. The delays will make the response useless if an application is time sensitive. A server downtime or Internet downtime usually renders the devices useless, since nothing works without the server’s decision.
What is the solution?
As with your restaurant, the devices need to be empowered with autonomy. In your restaurant, you’ll have given them recipes, guidelines, benchmarks, best practices and even devices like thermometers for temperature measurement and pomodoro timers for timing their recipes.
That’s what we need to do for devices to. Here’s how autonomy is achieved in edge computing.
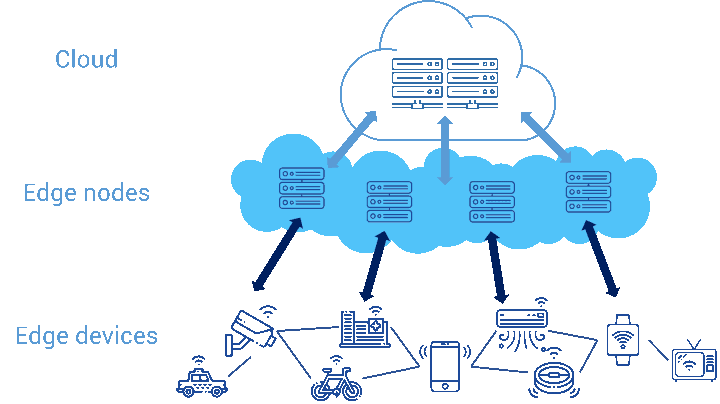
- The devices which gather data are usually beefed up with more processing power, memory and storage. In devices like Raspberry Pi, it is possible to add more power to the existing devices. But often, that is not possible, so providers release a new version with more power. E.g., the latest Google Home unit comes with a faster processor, more RAM and more storage. Google is trying to turn their Home unit into a autonomous device with its own copy of Google Assistant that can even execute some instructions, such as those for controlling your smart home, without a connection to Internet.
- If it is not possible to beef up existing devices or even release new ones with more power, then a new cluster of devices (e.g. a couple of desktop computers) is added at the same location as data gathering devices. This cluster will have the required computing power. The data gathering devices are then made to connect to the local cluster rather than the cloud on Internet.
- An arrangement, where either the local devices are beefed up or new powerful devices are added near the existing devices, is called an edge. The word ‘edge’ is used before the cloud servers are referred to as a ‘centre’. So with the cloud at the centre, all the IoT device are at the edge. In edge computing, we are empowering the edges by taking some load away from the centre.
- Just like you as the restaurant’s chief chef handed over intelligence to your junior chefs in the form of guidelines, recipes and benchmarks, the cloud at the centre hands over the intelligence to the edge.
- The edge operates autonomously without help from the cloud. Based on the data gathered from sensors, the edge applies algorithms and makes decisions autonomously. There are two advantages from this.
- There is no round trip to the cloud. Since the decision is made locally, there is no delay.
- No Internet connection is required for day-to-day operation. The decisions are all local. Internet connection is only needed at certain times of the data as discussed in the next point.
- No longer requiring help from the cloud, the edge only syncs up with the cloud at certain points during the day. This is usually for reporting what happened throughout the day in the form of records in an agreed format. The cloud analyses the data and improves its decision making algorithm and hands the new algorithm (if any) to the edge.

What changes are required to switch to edge computing?
In fact, that should be a whole new topic to discuss in another post. So I’ll leave the question hanging here. Be sure to watch out for the next post about the requirements to convert a cloud-based system to an edge-based system.
Conclusion
Edge computing is a new way of approaching a system that has been around for at least a decade and will continue to grow for decades to come. Instead of a central unit being responsible for the smooth functioning of a system distributed across the world, each part of that system will be autonomous and look out for its own, while looking to the centre only for guidance.