
In my 100th Tech 101 blog post, I am writing about a topic that I am yet to cover — Machine Learning. With the field now fairly mature and plenty of programming languages and companies supporting it with excellent software, it is high time for me to educate my readers on what exactly machine learning is.
In layman language, machine learning is a branch of artificial intelligence. Machine learning uses statistical methods, a branch of mathematics. It enables a computer to recognise patterns from data. Using machine learning, a computer make predictions from data, based on previous data that it has already learnt from. Let’s learn more.
Let’s simplify the above paragraph further, by looking at all the phrases that hold importance.
Branch of artificial intelligence

Artificial intelligence is the ability of a computer to observe data and attempt decisions on its own with little or no human intervention. Machine learning is a branch of artificial intelligence and is the most widely used one. Why?
Usage of statistics
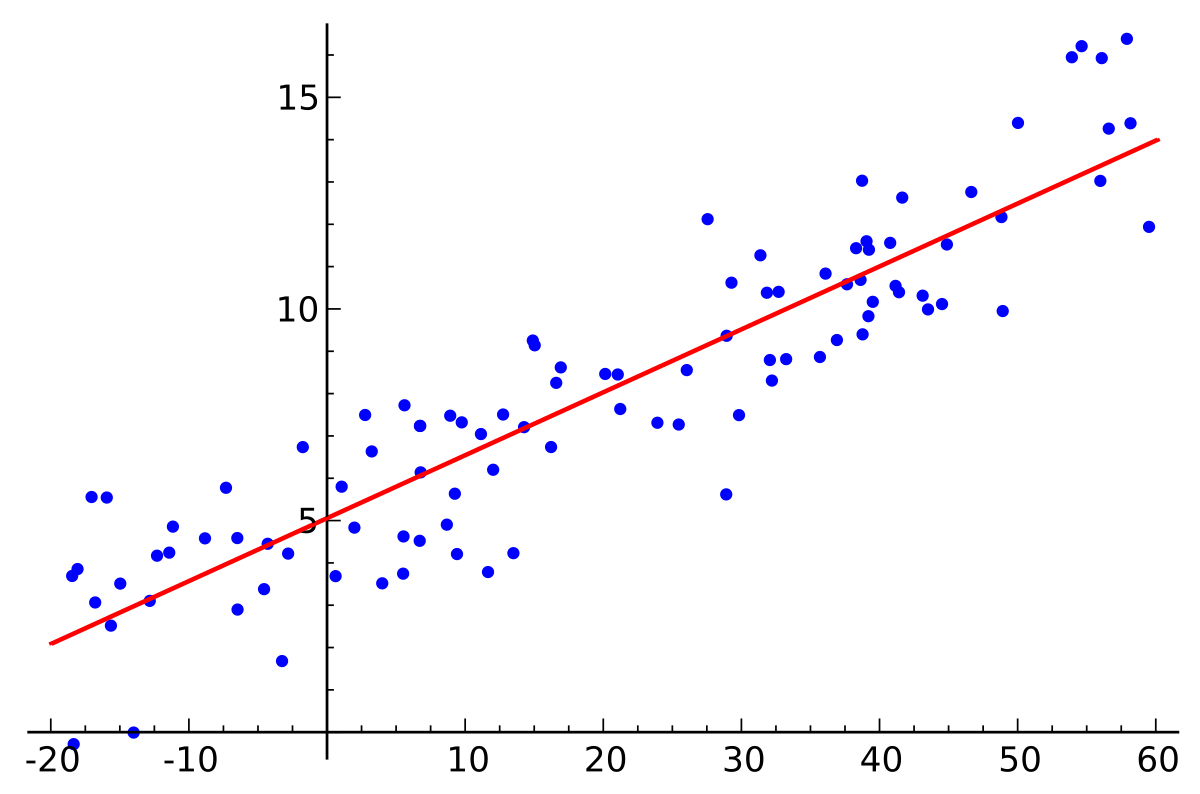
Yes, folks. There is nothing radically new about how a machine learns from data. It’s the same thing that humans have been doing for 3 centuries since statistical methods were formalised and widely used since the industrial revolution. Except, a computer does it at lightning speed, with virtually no mistakes and without getting bored. While other branches of artificial intelligence may lead to ambiguities, which a computer is terrible at dealing with, machine learning uses the strengths of a computer.
The most used statistical method is regression. Regression concludes something from the data available, but makes corrections to the conclusion as new data comes in. As more data becomes available, the conclusions become more and more accurate.
Pattern recognition

Humans have been recognising patterns from data since evolution. Recognising your spouse, knowing what weather it is, reading and the change of behaviour in front of authorities are all examples where you recognise a pattern based on the data available to you. From your five senses, you receive inputs to your brain, which sorts the necessary data and arrives at a conclusion and an appropriate behaviour. Machine learning does the same. It reads and sorts through data input and arrives at an output based on algorithms.
Predictions

After recognising a pattern, humans can predict with reasonable accuracy what happens next. The accuracy of prediction increases as humans see the pattern repeatedly. You can easily predict that a pouting child may throw a tantrum next and that dark clouds will lead to rain. Machine learning lends that power to machines. Based on a pattern, machines can be programmed to predict an outcome.
Continuous learning with more data
Not all dark clouds lead to rain. You will learn that the more you see dark clouds. Over time, you will learn to recognise other variables that lead to rain in addition to dark clouds and how much those variables influence the probability of rain. With more experience, you get better. A computer too learns more, the more it sees. It makes a prediction and matches it against the actual outcome. If they match, then the computer assumes that its algorithm is correct. Otherwise it adjusts some values to its formula, so that it has a chance of better accuracy during the next prediction.
Training data
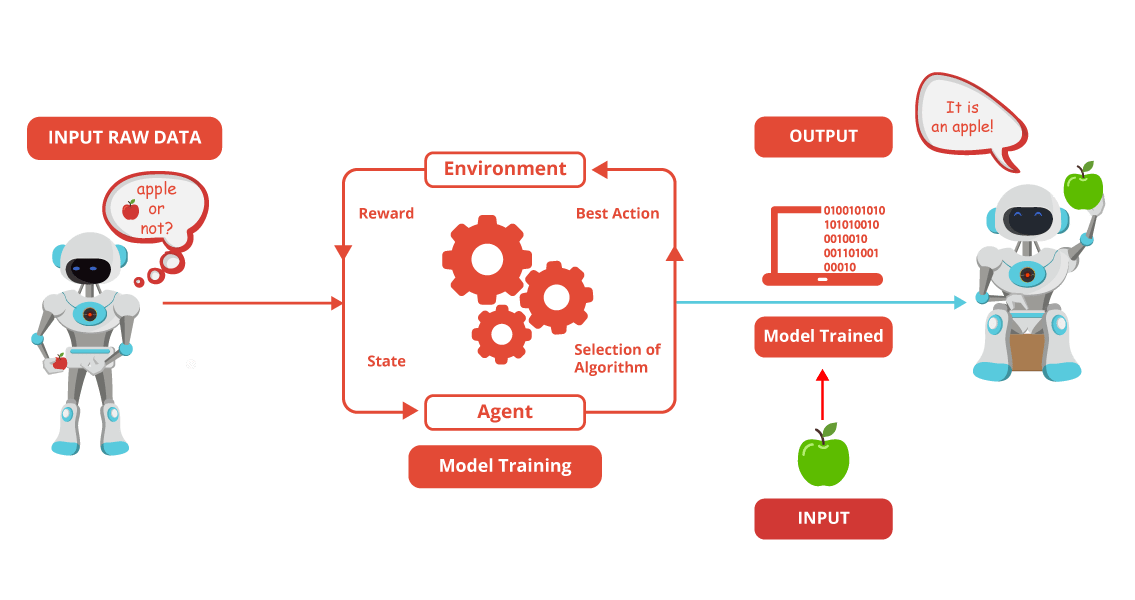
Machine learning cannot work without past data. The first step in machine learning is to train a computer. The initial database is manually fed into the machine learning system. This initial database is called a training database.
Training database can be tiny for a simple problem with one or two variables, or it can flow into Gigabytes for a problem as complex as speech recogntion. The more intense the training data, the better a system’s prediction.
Based on the training data, the system makes an initial regression formula for use for the next input.
Processing a new input
When a new input arrives, the system tries to make a prediction about the outcome. The actual result is either observed by the system or keyed in manually. The prediction is compared to the outcome. If it’s a match, then the formula is retained. But if it is a mismatch, the system makes some adjustments to the formula based on some learning algorithm. The new input is stored as part of training data and the new formula will be used for the next input.
Confidence
The confidence of a machine learning system is the ratio of the number of accurate predictions against the total number of predictions made. By definition, it also becomes the probability with which the system will make a right prediction. There is no universal definition of a good confidence ratio. It varies by the domain that the system is working on. E.g. some systems may accept 60% as a good confidence, while others need 95%.
E.g. if a shopping prediction system says that there is a 60% chance that a buyer buying milk also buys bread, then there is no harm in stocking up more bread. At worst, the bread will not clear the store shelf and can be given away. But a field like biotechnology needs more confidence for the chances of a new cure to work.
Conclusion
Machine learning is a growing field based on mathematics that has been around for 300 years. But the processing power that computing brings to us today makes those mathematical formulae much more lucrative. It has opened up new possibilities.