Software programs are like food and clothing. They come in all shapes and sizes. There are billions of programs. But all of them can be classified in a few categories. This post informs you about the different categories of software programs, what can be achieved with each, where they fall short and how you can decide which one you should build, or assemble a team for.
The topic seems very basic, but I feel that companies today are churning out too much code and too many variants of the same program for their own good. As a company, it is worth pausing and asking yourself what you really want to achieve for the users.
In part 1 of this series, we saw what VoIP is and how it is synonymous to traditional phone calls. We also listed some advantages of VoIP over traditional phone networks, that it is possible to set up your own VoIP network for use within your company. Finally, we saw that VoIP calls can be automated. One day your devices, such as home protection or a stock market ticker, will make an audio or video call to you via VoIP if something interesting occurs.
During the 1990s, there were only two ways to transfer voice communication from one place to another. The first type was radio communication, using gadgets like walkie-talkies. The second was telephone networks. At the turn of the century, the improved speed of the Internet was begging for a way to transfer voice in real time from one desktop computer to another. Enter VoIP or Voice over Internet Protocol.
What is VoIP?
VoIP is a way to transfer sound, mainly voice, from one device to another over the Internet in as much real-time as possible, similar to the way radio or phone does. But instead of a radio frequency or a telephone exchange, the medium over which your voice is carried from your device to the recipient’s device is the Internet. Please note that this is not the same as downloading a song in MP3 form and listening to it later. This is like a phone conversation where the voice is streamed from one end to another live.
In a telephone, a connection request is indicated to the recipient by ringing his/her device. A connection is established when the receiver picks up. VoIP too has the concept of connection request and establishment. Just like both the phones have a phone number for unique identity, VoIP devices have VoIP endpoints. These usually look like email addresses. Users connect to each other using endpoints. The act of dialling, ringing, picking up and having a conversation over a phone is known as a phone call. In VoIP, the entire cycle is called a VoIP session. Like calls can be recorded in modern telephony systems, VoIP sessions can be recorded too. And just like conference calls in telephones, VoIP sessions can happen with more than two participants.
In a VoIP call, the two parties use a software app or a dedicated device that connects to a VoIP service provider’s server over Internet. This is similar to the way that your landline telephone is plugged into a wall unit using an RJ11 cable and your mobile phone contains a SIM card that connects to the nearest tower belonging to your provider. The software connection to a VoIP server is established just like your web browser connects to the server of a website or your email software (e.g. Outlook, Thunderbird) connects to an email server. Once connected, the software app can request the server that it wants to talk to another person connected to the service. The server will then send a notification to the call recipient, who can choose to receive the call. The server then manages the path and the streaming of voice between the sender and receiver apps.
Advantages of VoIP
A phone communication requires dedicated hardware. You must use a telephone with a subscribed landline connection or a mobile phone with a SIM card whose service has been enabled.
The cost of a phone call depends on the distance between the participants. There are local, national and international calls all with different tariffs.
Phone networks can only be created and maintained by licensed service providers. You cannot start your own landline or GSM networks. It is possible to set up a local telephone network, also known as an intercom, as long as all the phones are within the same building / locality. But if your office is spread around the country or the globe, you cannot simply start a landline or a mobile network of your own. It would be illegal to. You need to purchase a service from BSNL, Vodafone, Rogers, AT & T, Movistar, etc. depending on where you are.
The phone numbers you receive from phone companies cannot be fenced such that only those from your company can call you. Phone numbers are globally accessible and anyone with your number can call you, whether they work in your organisation or not.
In contrast, VoIP can be used from a laptop, desktop computer and mobile phones with Internet enabled. Even a mobile phone which has no SIM card, but has access to Internet over WiFi is ready for VoIP. All you need is a software app that can connect to the VoIP network of your choice.
Since all the calls are over the Internet, you only pay for your Internet package, whether you speak to your spouse in the next room or to your friend on the other side of the globe.
Also, it is possible to set up your own VoIP network for communication between the multiple offices owned by your company across the world. Based on your access control, the rest of the Internet may be allowed to dial into your VoIP network.
Proprietary VoIP networks
Just like any software solution, VoIP comes in proprietary and open solutions. In proprietary solutions, you need to download the software or purchase the VoIP hardware that is released by the company providing the solution. The dedicated software or hardware automatically connects to the VoIP servers of the solution-providing company, without letting you know where they connect to or without allowing you to set any parameters for the connection. Usually, proprietary solutions allow people to talk using only their software and only to those people who have joined their network and who also use their software. Cross-platform VoIP calls did work for certain companies, but the solutions didn’t last.
Some proprietary VoIP solutions
Skype (now owned by Microsoft) was one of the first VoIP solutions. They broke ground at the start of the millenium, making VoIP a household name. Other solutions followed over the next decade: Google Talk, Yahoo voice chat, etc. Other than Skype, most other solutions were simply voice add-ons to their chat applications. With the success of Android and iPhone, Viber and FaceTime became some of the earliest VoIP apps available for smart phones. The success of Viber prompted WhatsApp to add audio and video to their otherwise text-only application. Google scrapped their erstwhile Google Talk solution and rebuilt a new solution called Hangouts. Hangouts remains one of the very few VoIP offerings that works purely from a browser and does not need an app. Google have not settled for their robust Hangout app and instead confused the users of their Play Store with another app named Duo. Other companies such as Zoom started their own VoIP solutions mainly with the intention of business conference calls where multiple participants can hold meetings by signing into a pre-determined ‘meeting room’.
All of the above solutions are proprietary and incompatible with each other. Skype cannot talk to WhatsApp, whose users cannot join a Hangout, whose users cannot converse with a user over FaceTime. This dreaded situation is called ‘vendor lock-in’. A user has to either confine him/herself to talk to users who also use their solution. Or they have to download / purchase multiple solutions to include everyone. Sometimes, even that’s not possible. For instance, even if an Android user is ready to pay an arm and a leg, Apple simply will not make an Android FaceTime app.
Open solutions
How will it be if we can use an open VoIP protocol that lets us set up our own VoIP server, and one that can chat with other open VoIP servers. Instead of being tied in to specific software apps from vendors, users can have a choice of apps ranging from basic to advanced, which can be programmed to connect to any VoIP server of their choice. Why not two VoIP servers? One for family and one for work. Can we build an ecosystem of VoIP apps and providers, where a user can simply change from app to app until he / she finds one that is right for him / her and then can simply switch from one VoIP provider within that favourite app to another based on the time of the day, one for casual purposes and one for work?
Yes, we can. That is promise of two protocols named SIP (Session Initiation Protocol) and H.323, which are open protocols. We will learn more details about those protocols in part 2 of the series. In this post, I’ll simply summarise that any SIP-compliant app can connect to any SIP-compliant VoIP provider. The providers of one network may set up their servers such that the contacts and sessions of every user be accessible to other providers.
Ekiga is an example of a VoIP desktop software that can connect to any VoIP server that supports SIP and H.323
Conclusion
Radio communications assisted the world during the World Wars. Telephones changed the face of voice communication between the 1950s and 1990s. But VoIP has democratised the way people speak to each other, making voice and video calls available to anyone with a device that has Internet, front-facing camera and a microphone, at a very reasonable price.
With VoIP making its way into the Internet of Things, it may even be possible in the future to speak to your home’s virtual assistant to get things done while you are away. Your home’s security camera may automatically dial you with a VoIP call if it detects something fishy. It remains to be seen how much more advanced this technology will turn out to be.
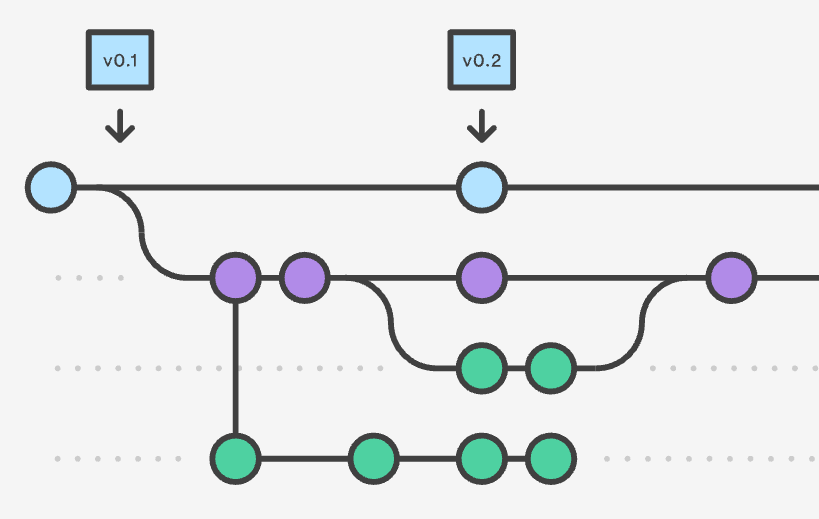
In the last post, we saw how version control system such as Git helps three poets, i.e. Nancy, Tommy and yourself write a poem and maintain several versions of it in a secure database, so that you can go back to an older version and start over again if you wanted to. We saw how only the changes across each version is saved. We also saw how the poets commit their own changes to a local repository, push them to a central repository and pull others’s changes into their own repositories.
In this post, we will see more advanced concepts such as branching, merging and conflicts. Fear not, these hard to understand concepts will be explained in a lucid manner. Continue reading “How version control works: Advanced”
…. thus goes a famous nursery rhyme from our childhood. How is it relevant to version control? In this post, you are going to imagine yourself as an author of the afore-mentioned nursery rhyme, working with a few more colleagues. Using that example, we will see how version control software works.
One of the biggest technological advances in this decade is the usage of machines hosted by server giants like Amazon and Google for our businesses, in the form of AWS and Google Cloud Compute. Not only do these companies offer machines, but they also offer specific services such as databases, service to send SMS, online development tools and backup services. These services are collectively referred to as PaaS or Platform-as-a-Service.
Over the last two years, another new concept has rapidly caught, mainly thanks to Amazon’s Lambda. We call this FaaS or Function-as-a-Service, where instead of running an entire software program or a website throughout the day, we simply run a single function, such as sorting a list of million names or converting the format of 50 videos from MPEG to AVI, etc on a remote machine which stays on for only the duration of the time that our function runs and then shuts down. By not keeping machines running all day, maintenance and operational costs go down significantly. This particular way of running machines for a specific short-term purpose and then shutting them down is now termed as ‘serverless’ architecture. Continue reading “Serverless architecture”
In the last article Introduction to clean architecture: Part 1, we saw how clean architecture is a set of principles for designing software such that the purpose of a software program is clear on seeing its code and the details about what tools or libraries are used to make it are buried deeper, out of sight of the person who views it. This is in line with real world products such as buildings and kitchen tools where a user knows what they are seeing rather than how they are made.
In this article, we will see how a very simple program is designed using clean architecture. I am going to present only the blueprint of a program. I won’t use any programming language, staying true to one of the principles of clean architecture, i.e. it doesn’t matter which programming language is used.
The simple program
In our program, we will allow our system to receive a greeting ‘Hi’ from the user while greeting him/her back with a ‘Hello’. That’s all we need to study how to produce a good program blueprint with clean architecture.
Where do we start
I have outlined this in the post An effective 2-phase method to gather client requirements. When given a problem, we must always start with who the user are and how the system work from their points of view. Based on the users, we should build possible use cases.
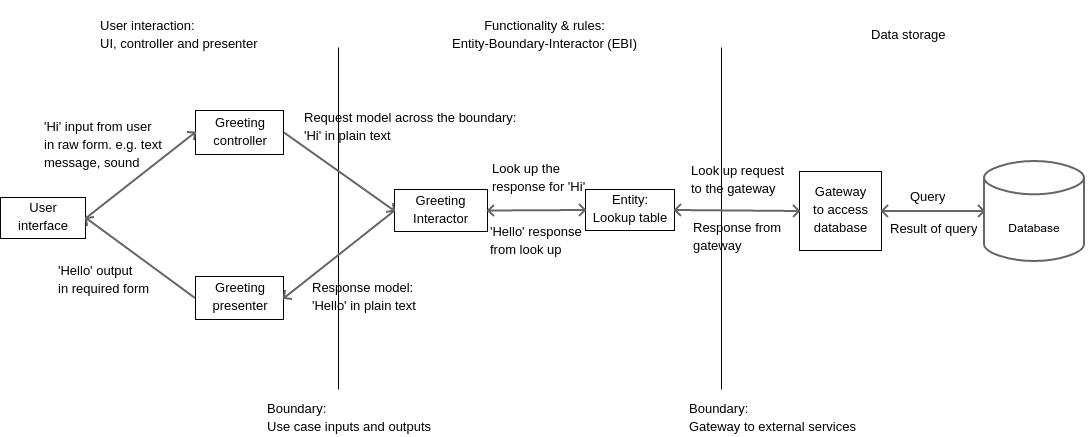
In our system, we have a single user who greets our system. Let’s call him/her the greeter. Let’s just use the word ‘system’ to describe our greeting application. We have just one case in our system which we can call, ‘Greet and be greeted back’. Here’s how it will look.
The greeter greets our system.
On receiving the greeting ‘Hi’ (and only ‘Hi’), our system responds with ‘Hello’, which the greeter receives.
Any greeting other than ‘Hi’ will be ignored and the system will simply not respond.
This simple use case has two aspects.
It comprehensively covers every step in the use case covering all inputs and outputs. It distinctly says that only a greeting of ‘Hi’ will be responded to and that other greetings will be ignored without response. No error messages, etc.
The use case also has obvious omissions. The word ‘greet’ is a vague verb which doesn’t say how it’s done. Does the greeter speak to the system and the system speak back. Does the greeter type at a keyboard or use text and instant messaging? Does the system respond on the screen, shoot back an instant message or send an email? As far as a use case is concerned, those are implementation details, the decisions for which can be deferred for much later. In fact, input and ouput systems should be plug-and-play, where one system can be swapped for another without any effect on the program’s core working, which is to be greeted and to greet back.
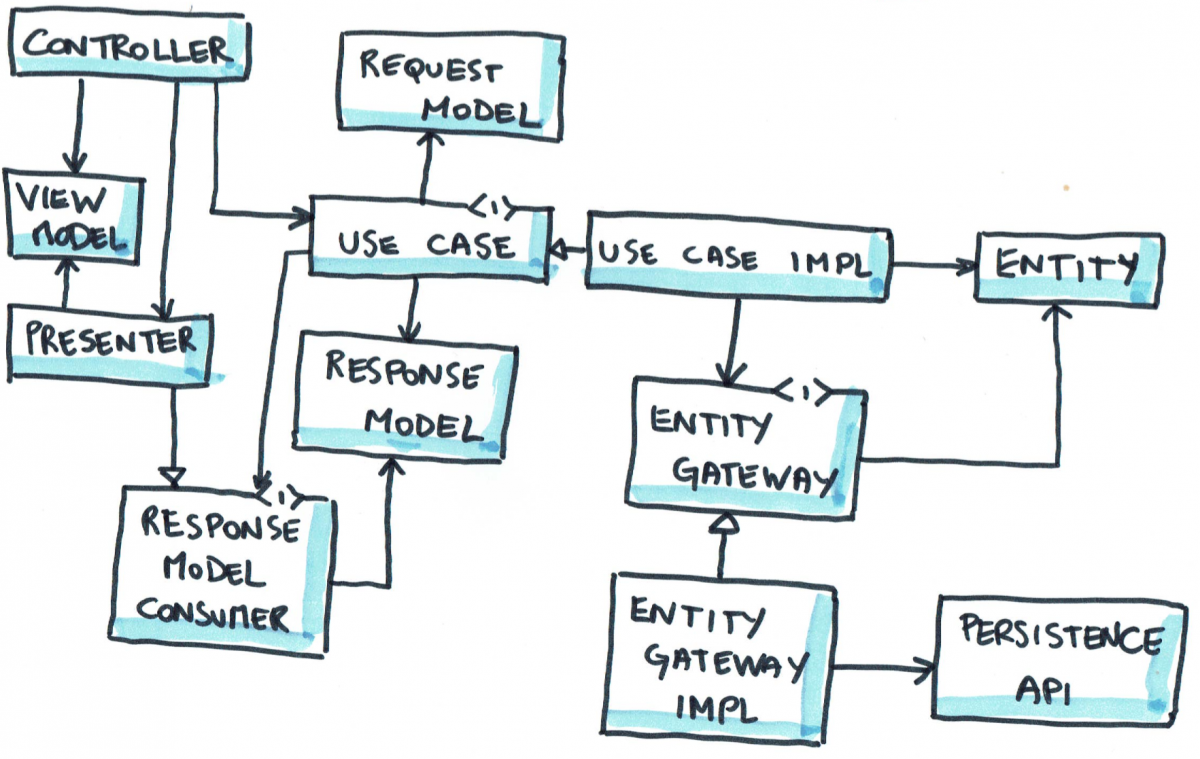
The EBI system
Components of clean architecture in our Greeting program.
Once the requirements are clear, we start with the use cases. The use case is the core of the system we are designing and it is converted into a system of parts known as the EBI or Entity-Boundary-Interactor. There are 5 components within the EBI framework. Every use case in the system is converted to an EBI using these five parts.
Interactor (I): The interactor is the object which receives inputs from user, gets work done by entities and returns the output to the user. The interactor sets things in motion like an orchestra director to make the execution of a use case possible. There is exactly one interactor per use case in the system.
Entities (E): The entities contain the data, the validation rules and logic that turns one form of input into another. After receiving input from the user, the interactor uses different entities in the system to achieve the output that is to be sent to the user. Remember that the interactor itself must NEVER directly contain the logic that transforms input into output. In our use case, our interactor uses the services of an entity called GreetingLookup. This entity contains a table of which greeting from the user should be responded to with which greeting. Our lookup table only contains one entry right now, i.e. a greeting of ‘Hi’ should be responded to with ‘Hello’.
Usually, in a system that has been meant to make things easy, automated or online based on a real world system, entities closely resemble the name, properties and functionality of their real world equivalents. E.g. in an accounting system, you’ll have entities like account, balance sheet, ledger, debit and credit. In a shopping system, you’ll have shopping cart, wallet, payment, items and catalogues of items.
Boundaries (B): Many of the specifications in a use case are vague. The use case assumes that it receives input in a certain format regardless of the method of input. Similarly it sends out output in a predetermined format assuming that the system responsible for showing it to the user will format it properly. Sometimes, an interactor or some of the entities will need to use external services to get some things done. The access to such services are in the form of a boundary known as a gateway.
E.g., in our use case, our inputs and outputs may come from several forms such as typed or spoken inputs. The lookup table may seek the services of a database. Databases are an implementation detail that lie outside the scope of the use case and EBI. Why? Because, we may even use something simpler such as an Excel sheet or a CSV file to create a lookup table. Using a database is an implementation choice rather than a necessity.
Request and response model: While not abbreviated in EBI, request and response models are important parts of the system. A request model specifies the form of data that should be sent across the boundaries when requests and responses are sent. In our case, the greeting from the user to the system and vice-versa should be sent in the form of plain English text. This means that if our system works on voice-based inputs and outputs, the voices must be converted to plain English text and back.
Controllers
With our EBI system complete to take care of the use case, we must realise that ultimately the system will be used by humans and that different people have different preferences for communication. One person may want to speak to the system, while another prefers instant messaging. One person may want to receive the response as an email message, while another may prefer the system to display it on a big flat LCD with decoration.
A controller is an object which takes the input in the form the user gives and converts it into the form required by the request model. If a user speaks to the system, then the controller’s job is to convert the voice to plain English text before passing it on to the interactor.
Presenters
On the other side is a presenter that receives plain text from the interactor and converts it into a form that can be used by the UI of the system, e.g. a large banner with formatting, a spoken voice output, etc.
Testability
Being able to test individual components is a big strength of the clean architecture system. Here are the ways in which the system can be tested.
Use case: Since the use case in the form of EBI is seperated from the user interface, we can test the use case without having to input data manually through keyboards. Testing can be automated by using a tool that can inject data in the form of the request model, i.e. plain text. Likewise the response from the use case can be easily tested since it is plain text. Also individual entities and the interactor can be seperately tested.
Gateway: The gateways such as databases or API calls can be individually tested without having to go through the entire UI and use case. One can tools that use mock data to see if the inputs to and outputs from databases and services on the Internet work correctly.
Controllers and presenters: Without involving the UI and the use case, one can test if controllers are able to convert input data to request model correctly or if presenters are able to convert response model to output data.
Freedom to swap and change components
Interactors: Changes to the interactors are often received well by the entire system. Interactors are usually algorithms and pieces of code that bind the other components together, usually a sequence of steps on what to do. Changes to the steps does not change any functionality in the other components of the system.
Entities: Entities are components that contain a lot of data and rules relevant to the system. Changes to entities will usually lead to corresponding changes in the interactor to comply with the new rules.
Boundaries: Boundaries are agreements between the interactor and external components like controllers, presenters and gateways. A change to the boundary will inevitably change some code in the external components, so that the boundary can be complied.
UI: With a solid use case in place, you can experiment with various forms of UI to see which one is most popular with your users. You can experiment with text, email, chat, voice, banner, etc. The use case and the gateway do not change. However, some changes to the UI can cause a part of the controller and the presenter to change, since these two are directly related to how the UI works.
Controller and presenter: It is rare for the controller or presenter to change in their own rights. A change to the controller or presenter usually means that the UI or the boundary has also changed.
Conclusion
Clean architecture seperates systems such that the functionality is at the core of the system, while everything like user interface, storage and web can be kept at the periphery, where one component can be swapped for another. Hopefully, our example has given you a good idea about how to approach any system with clean architecture in mind.
If you ever walk through the kitchen appliances section of a shopping mall, you will see lemon juicers made of steel, plastic and wood. The raw material doesn’t matter. One glance at the simple tool and you know what it is. The details about what the juicer is made of, who made it and how the holes at the bottom were poked become irrelevant.
Similarly, if you look at a temple, you know that it is a temple. A shopping mall screams at you to come shop inside. Army enclaves have tell-tale layouts, stern looking guards and enough signboards to let you know that you should stay away and avoid trespassing.
Once there lived a king whose land produced plenty of grains. The king made a policy to secure 1/5th of the produce and have it distributed to the poorest homes in his land for a subsidy.
The kingdom had a main distribution centre that was responsible for buying grains from the farmers and then distributing them to the local village distribution centres. Due to the sheer number of farmers and the number of villages to whom the grains were to be distributed, this main centre was overworked. Being busy, this centre would sometimes forget to reserve 20% for the poor neighbourhoods and send part of it to the regular villages. Sometimes, they would delay the distribution to the poor neighbourhoods.
The king wanted to change the system, ensuring that the poor got what they were promised. He set up a seperate distribution centre for the poor at the kingdom’s main temple. He instructed the farmers to take 1/5th of their produce to this centre and offer it to the kingdom’s chief deity at the temple. The rest of the produce was to be taken to the capital’s regular distribution centre. The temple’s distribution centre was immediately effective and the poor got the portion that they were promised for a subsidy.
What about OpenGL?
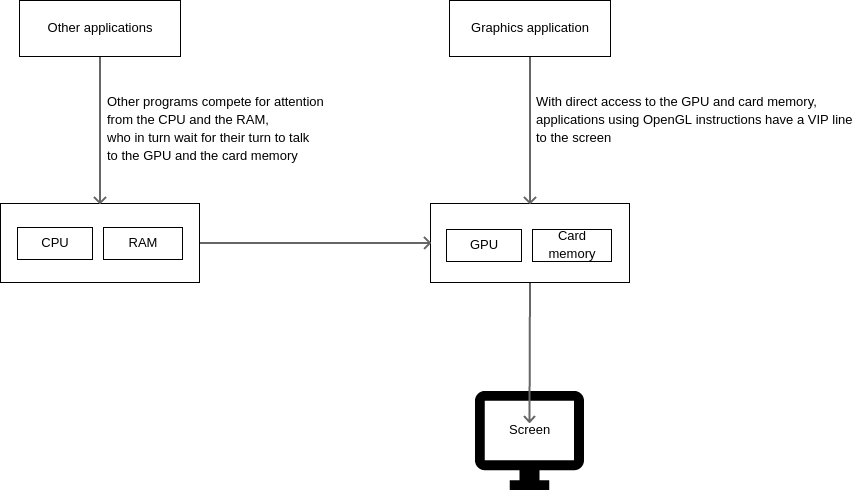
The moral of the story is that if you want something to be done on priority, then a seperate system must be set up for it. In computer graphics, OpenGL (Open Graphics Library) is a system that makes sure that apps forgo the computer’s main memory (RAM) and processor and instead use a seperate memory and processor (GPU or Graphics Processing Unit) inside the graphics card to which the screen is attached. The main memory and the CPU is where all applications compete for attention, but since drawing happens on the dedicated graphics memory and GPU, even the most complex of shapes on the screen are drawn very quickly, though you play an intense computer game with a lot of moving scenes.
How OpenGL works
What is OpenGL?
The world of computer graphics got really confusing in the 1990s when competing companies made competing solutions. None of the solutions were compatible with each other. One hardware would work with one app on one operating system, while not working on others. This made the progress of computer graphics really slow and cautious as graphics application makers were wary of permanently locking into a vendor for each solution. Everyone wanted some standards and interoperability.
At the end of the 1990s, companies that make software for developing apps (e.g. Google, Microsoft, Mozilla), companies that make operating systems (e.g. Microsoft, Apple) and companies that make graphics cards (e.g. NVIDIA, ATI, Intel) came together to make the Khronos group. This group made a set of specifications. The specification was a list of instructions that can be used by programmers and supported by operating systems and hardware for the most common drawing operations.
Instructions are as simple as placing a single dot on the screen or as complex as drawing 3-dimensional structures for an entire scene, complete with lighting and shadows. Instructions use the GPU and the dedicated memory provided on the graphics card made by the hardware vendors. The specifications are updated every year as the world of graphics evolves and more complex things are possible.
How OpenGL helps software programmers
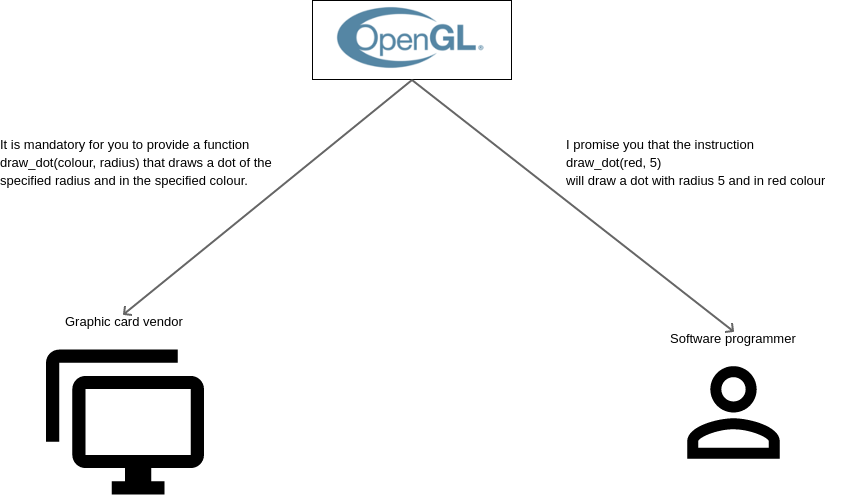
Any specification or user’s manual creates an expectation about the set of things possible in a piece of technology. If you are given even an unbranded washing machine, you know that you can wash and dry clothes in it. Sure, there are semi-automatic machines and fully automatic models. But the behaviour is standardised. Put dirty clothes in, get them washed in water, get them dried and take out clean clothes.
The OpenGL specification creates expectations for the software programmers about a set of outcomes that a graphics system can achieve. Programmers are promised a set of instructions with what results to expect from them. The specification says that if they use instruction X, then it will lead to result Y. Since the OpenGL standard is adopted by multiple vendors, the programmers know that the same instructions will work on multiple operating systems and with multiple hardware vendors, as long as they promise to adhere to OpenGL.
How OpenGL specification standardises computer graphics instructions
Before OpenGL, there was no such standard and each hardware and operating system had their own unique instructions which didn’t work with others. Even the instruction to place a tiny dot on the screen would fail across multiple systems and programs were made for every system that the company wanted to support.
How OpenGL helps vendors
A company that makes washing machines knows that the customer expects a machine to do two things. Wash clothes in water and dry clothes by spinning. The vendor can provide other fancy details such as voice controlled input, temperature control of water or remote control through a smart phone. But if the machine doesn’t wash and dry, then its a failure. By default, the vendor is given those two goals for his/her product.
Vendors of operating systems and graphics cards are to provide at a minimum all the instructions that are specified by OpenGL. They have a goal to start with. They can add other fancy things that differentiate their product from others, but if they promise to adhere to OpenGL, then the instructions in the specification are to be mandatorily provided for.
Some companies are very savvy at graphics than others. These companies will make new breakthroughs in the field and will expect OpenGL to support those new features in the future. OpenGL allows vendors to package new features as extensions to the regular functionality, along with how to name those add-ons. Every year, vendor-specific extensions are reviewed by the OpenGL community and the most promising ones are inducted as new instructions in the specification. Every other vendor will need to support the new instructions too. Thus OpenGL provides a way for vendors to innovate and pave the way for the future.
Conclusion
From a chaotic mess of too many narrow solutions, OpenGL has united the community of computer graphics into an organised industry with standards. The computer graphics industry has promptly responded. From cartoonish 2-D characters that we saw in the 90s, on-screen characters have started resembling the real-world equivalents, complete with facial expressions and behaviour. As more vendors and programmers enter the field and virtual world mingles with reality, we can only watch in amazement as technology improves.
Adarsh is a young chocolate maker whose chocolate products, especially chocolate sauce, are extremely popular in town. His chocolate sauce is loved by retails shoppers and restaurant kitchens alike. Restaurants use his chocolate products as part of their own recipes such as sundaes. It’s a wonder, because Adarsh has been making chocolates for only two years. Food connoisseurs are impressed with Adarsh. They have been to his shop floor and they attribute his success to his meticulous attention to detail. One particular connoisseur, Bindia, writes for the ‘Foodies’ section of the town newspaper and is excited at the chance to interview Adarsh about his success. Here is how their interview goes.